Using Metrics in Software Engineering Management
Principles for measuring it right

There is a lot of data in software development. Teams track their tickets with software systems. We record every code commit. All the primary operations across the software lifecycle, including releases, testing, and operations, have multiple metrics attached to them.
With all of that, it is somewhat surprising that metrics haven’t been more critical for Engineering Managers (EMs) recently. Looking at the past decade, the main metrics EMs would consistently use would be velocity and some kind of ticket estimate. But that has quickly changed, and now the industry is scrambling to figure out how to improve effectiveness with all the suddenly available data.
Metrics’ Prime Time
Metrics came back into the mainstream for management when DORA metrics connected a few measurements to highly-effective teams. More recently, SPACE metrics presented an approach to thinking about developer productivity. And on the back of that, it seems like a hundred software engineering tracking tools have appeared in the market.
This movement into data-driven software engineering management has great potential to be positive and lead teams to better outcomes. It is still surprising how many decisions that involve much effort and resources are made primarily based on opinions. For example, many significant refactoring or rebuilding projects I have seen (and led!) were based on subjective opinions that some code was not good enough. Unfortunately, as an old friend used to say, “there are two types of code: good code and code you didn’t write.” Having metrics available for better decision-making can be a significant step toward more productive software engineering organizations.
However, there are always risks and challenges when adopting metrics. They spotlight specific areas of the work environment by showing people how a particular part of it is going. If we are not careful when adopting them, we might highlight the wrong areas, creating unproductive and sometimes even harmful behaviors.
Tell Me How You Measure Me
The main challenge is that organizations are driven toward metrics and what can be measured. If there are metrics available, now there are opportunities for optimization. For example, annual and quarterly results and performance reviews are metric-driven. Making metrics available for a particular characteristic will often lead to efforts to analyze and optimize it.
“Tell me how you measure me and I’ll tell you how I will behave.” — Eliyahu M. Goldratt
And that can lead to some anti-patterns:
Using metrics as the main tool to evaluate individuals
This is the most discussed anti-pattern. It feels old to keep repeating that we should not measure engineering efforts based on lines of code (LoC). And while LoC is (almost) not talked about anymore, we now talk about the number of Pull Requests (PRs), the number of commits, and many other output-based metrics.
Metrics will drive individual behavior. If you evaluate engineers based on PRs, engineers will write more PRs. And I hope we understand that having more code is never the solution. It’s often the problem.
Focusing on individual metrics
Besides evaluating people, it is worth highlighting that simply having metrics available will drive people to improve them. Individual metrics can be positive, but they will also drive unwanted behavior in a team. If a team regularly reviews individual metrics, it drives individualistic behavior, often harming the team’s output.
A simple example is looking at the now trendy PR cycle time measurement. If what a team measure is individual cycle time (i.e., time to start and close a PR), engineers will open and close PRs as fast as possible. That is great, in theory, unless other engineers are waiting for a review on their PR but can’t find help because everyone is trying to solve their problem first.
Excessive focus on efficiency
The least visible (and, in my opinion, most harmful) challenge with metrics is the focus on efficiency that they bring. In other words, metrics make it easier to drive more output, even with the wrong outcome.
The basis of this problem is that a significant amount of work in any organization should never be done and delivers no value. Understanding this problem is the thinking behind waste in Lean Systems, KTLO in the current software engineering discussion, or failure demand. They are all similar concepts that say one thing: a part of the work teams do has no value.
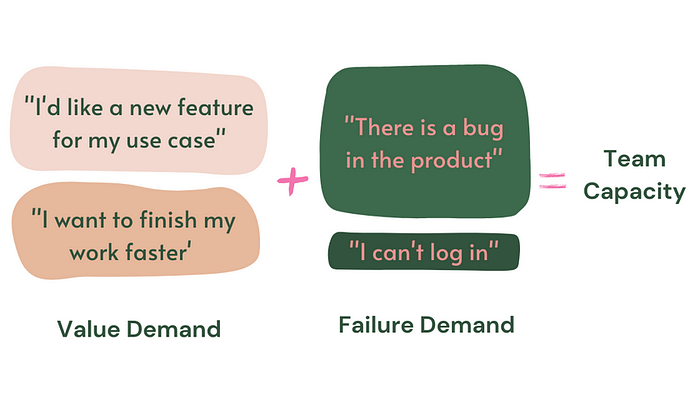
A recurring example is how teams sometimes focus too much on bug/incident time-to-resolution metrics, creating a perspective that “fixing bugs quickly” creates customer value when, in reality, not having the bugs in the first place would be much more appreciated.
Eye on the Prize
With all the challenges above in mind, it is worth reminding that metrics can be beneficial as long as teams use them to improve how to get to their desired outcomes. In other words, EMs need to apply metrics that help them improve the system of work, leading to better team results.
While doing that, there were a few principles I try to keep in mind in teams that I help manage:
Understanding value and non-value work
The essential step in any measurement a team can do is to understand what value and non-value work is and how much of each a team executes. Of course, there are different ways to look at value. Still, a simple way to define it is anything a customer will appreciate (new features, better performance, more stability), with everything else being considered waste (fixing bugs, dealing with incidents, refactoring low-quality code).
There will always be an amount of non-value work necessary, but teams should focus on eliminating it rather than becoming efficient at dealing with it.
Think about the flow of work
While process-specific metrics like PR cycle time, MTTR, and code review time are helpful, teams should use them to improve the overall flow of work, not in isolation. In other words, teams should understand the overall system first (i.e., how quickly can we deliver a project or feature from idea to production), to then move towards more targeted metrics for optimization.
Reducing the PR cycle time only makes sense if it helps reduce the overall time to deliver value. And teams need to understand the broader metric to make decisions around it.
Understand special causes and common causes
When looking at recurring metrics, it is also important to understand that every process has variations and the difference between special causes and common causes. In a software team, for example, the cycle time for PRs to be merged will have a natural variation based on their complexity and how the team works.
It is not uncommon to see teams acting on metrics as if they should be stable, taking action, and consuming effort in areas that will not lead to improvement. In the example above, teams should focus on common causes to reduce that variation (i.e., how long it takes for PRs to be reviewed) instead of acting on outliers (i.e., this sprint, the cycle time went up because someone was out sick).
Stabilize. And then improve
Lastly, understand that metrics with high variability will be impossible to improve. For example, suppose your cycle time varies from 1 to 30 days. In that case, any improvement a team attempts in the area will be hard to perceive, leading to process improvement churn, with lots of ideas and effort to improve things but no actual results.
The first path to any improvement effort is stabilizing a metric, meaning reducing the variation to a stable amount. In the example above, if ticket cycle time varies significantly, the first step would be to reduce the variation in the size of each ticket, making sure that tickets are split into similar effort parts. Once that is achieved, it will be much easier to experiment with improvements and understand if they are successful.
Metrics are here to stay
Metrics are not going anywhere in software engineering, and they will continue to be adopted more often as more tools and supporting data become available for teams to consume.
In this context, EMS must focus on applying the best metrics to their team according to their situation instead of just adopting what has been served because someone decided to buy a specific tracking software. Doing it right will lead to much better visibility in execution and results for their teams.
If you have found this content interesting, this post is part of a series on Leading Software Teams with Systems Thinking. More broadly, I write about leading effective software engineering teams. Follow me if you are interested in the area.

